How to Enable Auto-Renewal for SurferCloud Cl
How to Enable Auto-Renewal for SurferCloud Cloud Resour...






Ever wished you could directly ask questions to a PDF or technical manual? This guide will show you how to build a Retrieval-Augmented Generation (RAG) system using DeepSeek R1, an open-source reasoning tool, and Ollama, a lightweight framework for running local AI models.

Looking to simplify your API workflows? Apidog acts as an all-in-one solution for creating, managing, and running tests and mock servers. With Apidog, you can:
Save time and focus on perfecting your product. Ready to try it? UModelVerse supports the DeepSeek R1/V3 model, available for free.
DeepSeek R1, a model comparable to OpenAI’s o1 but 95% cheaper, is revolutionizing RAG systems. Developers love it for its:
Ollama lets you run models like DeepSeek R1 locally.
ollama run deepseek-r1 # For the 7B model (default)
DeepSeek R1 ranges from 1.5B to 671B parameters. Start small with the 1.5B model for lightweight RAG applications.
ollama run deepseek-r1:1.5b
Pro Tip: Larger models (e.g., 70B) offer better reasoning but need more RAM.

We’ll use:
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
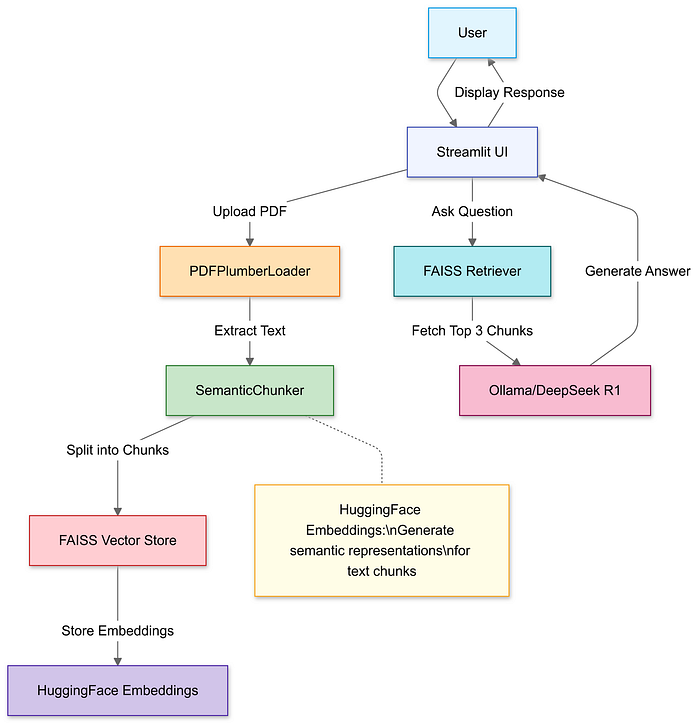
Leverage Streamlit’s file uploader to select a local PDF. Use PDFPlumberLoader to extract text efficiently without manual parsing.
# Streamlit file uploader
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
if uploaded_file:
# Save PDF temporarily
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# Load PDF text
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
Leverage Streamlit’s file uploader to select a local PDF. Use PDFPlumberLoader to extract text efficiently without manual parsing.
# Split text into semantic chunks
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)

Generate vector embeddings for the chunks and store them in a FAISS index.
# Generate embeddings
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
# Connect retriever
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # Fetch top 3 chunks
Set up a RetrievalQA chain using the DeepSeek R1 1.5B model.
llm = Ollama(model="deepseek-r1:1.5b") # Our 1.5B parameter model
# Craft the prompt template
prompt = """
1. Use ONLY the context below.
2. If unsure, say "I don’t know".
3. Keep answers under 4 sentences.
Context: {context}
Question: {question}
Answer:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
Integrate uploading, chunking, and retrieval into a cohesive pipeline.
# Chain 1: Generate answers
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
# Chain 2: Combine document chunks
document_prompt = PromptTemplate(
template="Context:\ncontent:{page_content}\nsource:{source}",
input_variables=["page_content", "source"]
)
# Final RAG pipeline
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)
Streamlit enables users to type questions and receive instant answers.
# Streamlit UI
user_input = st.text_input("Ask your PDF a question:")
if user_input:
with st.spinner("Thinking..."):
response = qa(user_input)["result"]
st.write(response)
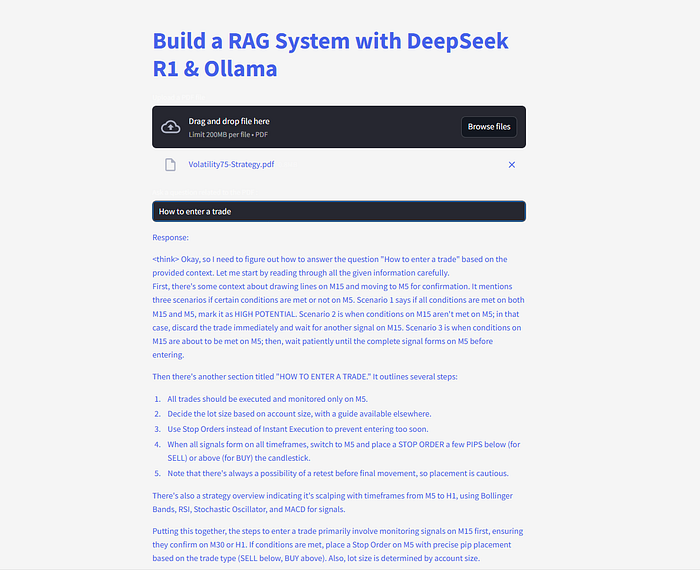
You can find the complete code here: https://gist.github.com/lisakim0/0204d7504d17cefceaf2d37261c1b7d5
DeepSeek R1 is just the beginning. With upcoming features like self-verification and multi-hop reasoning, future RAG systems could debate and refine their logic autonomously.
Build your own RAG system today and unlock the full potential of document-based AI!
Reposted from: Developing RAG Systems with DeepSeek R1 & Ollama (Complete Code Included) | by Sebastian Petrus | Jan, 2025 | Medium.



